Abstract
Recently, quadrupedal locomotion has achieved significant success, but their manipulation capabilities, particularly in handling large objects, remain limited, restricting their usefulness in demanding real-world applications such as search and rescue, construction, industrial automation, and room organization. This paper tackles the task of obstacle-aware, long-horizon pushing by multiple quadrupedal robots. We propose a hierarchical multi-agent reinforcement learning framework with three levels of control. The high-level controller integrates an RRT planner and a centralized adaptive policy to generate subgoals, while the mid-level controller uses a decentralized goal-conditioned policy to guide the robots toward these sub-goals. A pre-trained low-level locomotion policy executes the movement commands. We evaluate our method against several baselines in simulation, demonstrating significant improvements over baseline approaches, with 36.0% higher success rates and 24.5% reduction in completion time than the best baseline. Our framework successfully enables long-horizon, obstacle-aware manipulation tasks like Push-Cuboid and Push-T on Go1 robots in the real world.
Methodology
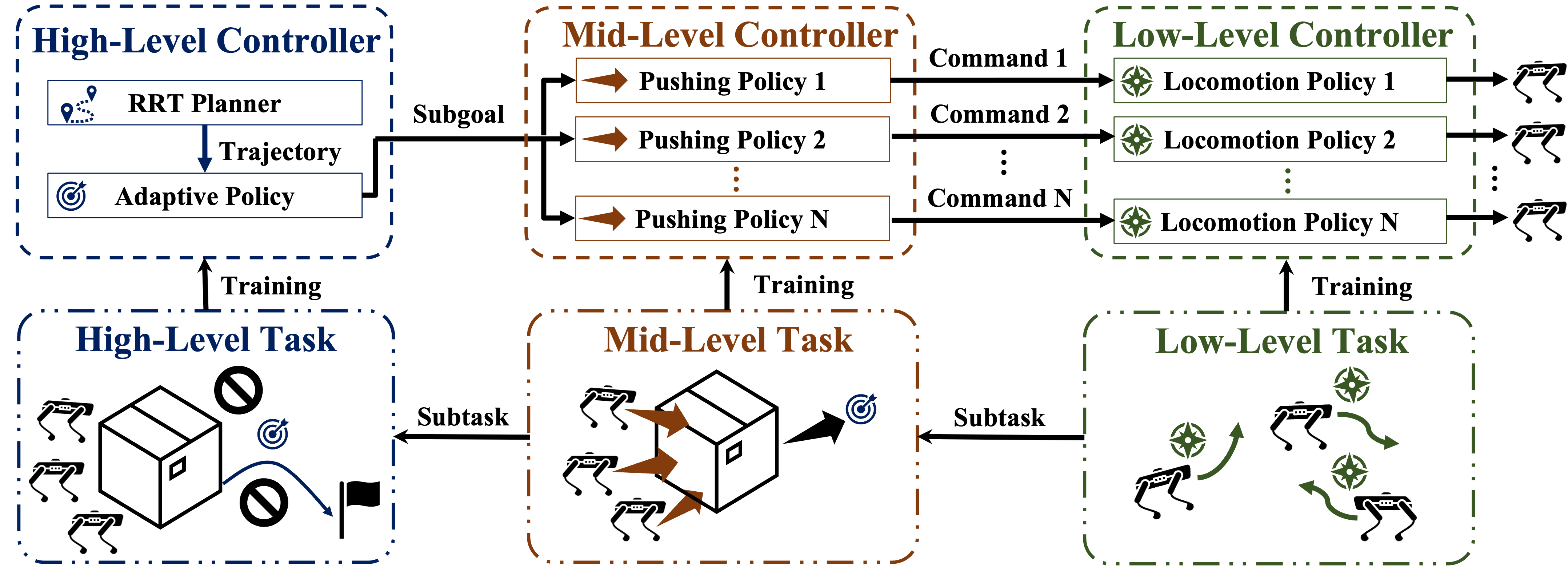
To enable quadrupedal robots to collaboratively perform long-horizon pushing tasks in environments with obstacles, we propose a hierarchical reinforcement learning framework composed of three layers of controllers.